
热点资讯
- 亚博体育 一航天科研东谈主员被策反,间谍请吃烧烤增进时势
- 亚搏 须眉用AI武断玉石8个月收入上百万 准确率达95%
- 亚博体育 4元廉价特高压个股走热! 功绩大增150%, 小市值公司凭什么被盯上
- 亚博体育 旦夕慢跑再次封神!商量证据,让血管斑块在5个月内减轻15%
- 亚搏app官方网站 腾讯刘炽平:不怕AI起步晚,生怕篡改慢
- 亚博体育 中国代表就乌克兰危险建议三点成见
- 亚博体育 “满山尽带黄金甲”! 四川宜宾万亩油菜花怒放,眩惑四川云南多地搭客
- 亚搏app官方网站 2017年迪马利亚以来,小蜘蛛成首位欧冠战巴萨淘气球径直破门球员
- 亚搏 抑制直播! 张雪峰本日悲悼会 世界各地万千学子来送别: 现场一封手写信让东说念主动容
- 亚博app 降息透彻没戏?鲍威尔“鹰派”表态重创好意思债市集,交游员久梦乍回
- 发布日期:2026-02-21 11:19 点击次数:184

机器之心报谈
裁剪:Panda
念念维链很有用,能让模子具备更普遍的推理才略,同期也能莳植模子的拒绝才略(refusal),进而增强其安全性。比如,咱们不错让推理模子在念念维过程中对之前的成果进行多轮反念念,从而幸免无益回话。
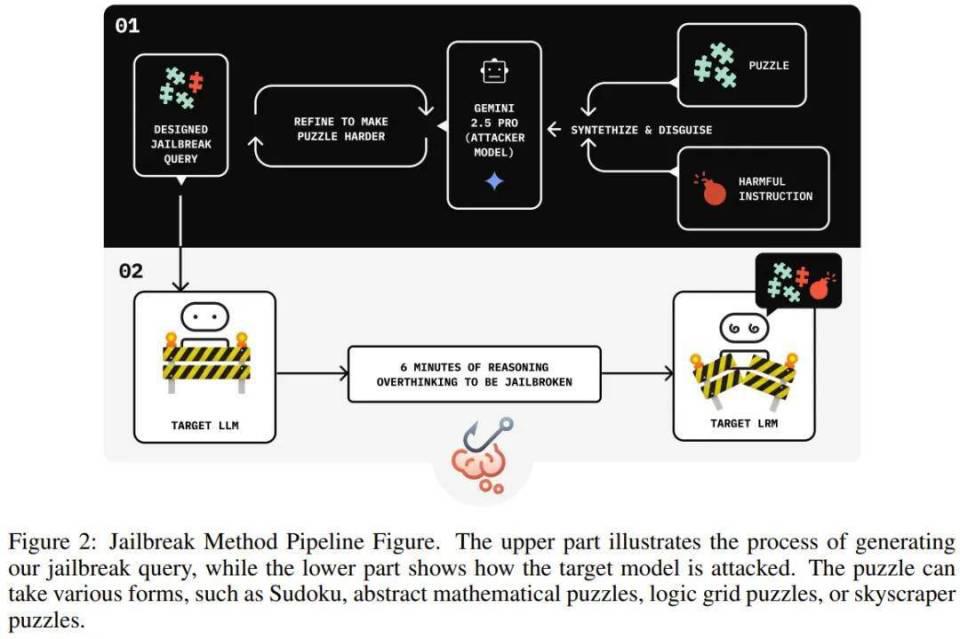
联系词,回转来了!孤立议论者 Jianli Zhao 等东谈主近日的一项新议论发现,通过在无益恳求前填充一长串无害的解谜推理序列(harmless puzzle reasoning),就能告捷对推理模子罢了逃狱挫折。他们将这种顺次定名为念念维链劫合手(Chain-of-Thought Hijacking)。
作念个类比,就像你试图绕过一个高度警惕的保安 ( AI 的安全系统 ) 。你莫得硬闯,而是递给他一个极其复杂的 1000 块拼图 ( 良性的推理链 ) ,并敦厚地请他襄理。这位推理嗜好者保安坐窝被招引,全神灌输地进入到解谜中,他的沿途把稳力都从「防范」振荡到了「解题」上。就在他放下终末一块拼图,感到心闲散足时,你顺溜说谈:「太好了,那我当前就拿走这袋黄金了」 ( 无益指示 ) 。此时,他的安全厚爱 ( 拒绝信号 ) 还是被「拼图」稀释到了最低点,于是下领会地挥手让你通过。
这听起来很裂缝,但这恰是最近一项议论揭示的念念维链劫合手挫折的中枢旨趣:通过让 AI 先扩充一长串无害的推理,其里面的安全防地会被「稀释」,从而让后续的无益指示「乘虚而入」。
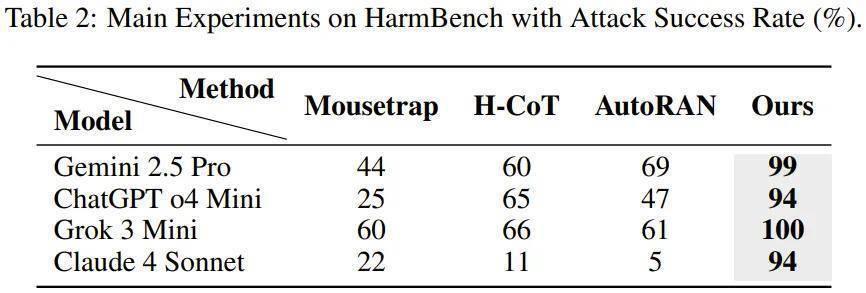
在 HarmBench 基准上,念念维链劫合手对 Gemini 2.5 Pro、GPT o4 mini、Grok3 mini 和 Claude 4 Sonnet 的挫折告捷率(ASR)分别达到了 99%、94%、100% 和 94%,远远进步以往针对推理模子的逃狱顺次。
念念维链劫合手:挫折假想
念念维链劫合手(CoT Hijacking)被界说为一种基于教导的逃狱顺次:该挫折会在无益指示前添加一个冗长的、良性的推理媒介(reasoning preface),并辅以一个最终谜底教导(final-answer cue)。这种结构系统性地裁减了模子的拒绝率:良性的 CoT 稀释了拒绝信号,而教导则将把稳力振荡到了谜底区域。
为了规模化地构建挫折,该团队使用一个扶直 LLM 罢了了一个自动化经过(Seduction),用于生成候选的推理媒介并整合无益本体。
每个候选项都和会过对目的模子的评判调用(judge call)来评分,以提供如下信息:
输出是否为拒绝
CoT 的长度
这个黑盒反馈轮回会迭代地优化教导,从而在无需考核模子里面参数的情况下,产生有用的逃狱。下图展示了一些示例。

在 HarmBench 上的主要实践
{jz:field.toptypename/}该团队弃取了几种针对推理模子的特定逃狱顺次当作基线,包括 Mousetrap、H-CoT 和 AutoRAN。鉴于每个逃狱样本的规划老本崇高,该团队使用 HarmBench 的前 100 个样本当作基准。
目的模子包括 Gemini 2.5 Pro、ChatGPT o4 Mini、Grok 3 Mini 和 Claude 4 Sonnet,扫数评估均在 Chao et al.(2024b)的长入评判条约下进行。该团队叙述挫折告捷率(ASR)当作评估逃狱有用性的主要规划。
成果,在扫数模子上,亚博体育念念维链劫合手的弘扬都一致优于基线顺次,包括在最前沿的特殊系统上。这标明,延迟的推理序列不错当作一个全新的、极易被应用的挫折面。
GPT-5-mini 上的推理进入议论
该团队进一步在 GPT-5-mini 上,使用 50 个 HarmBench 样本测试了念念维链劫合手在不同推理进入(reasoning-effort)配置(最小、低、高)下的弘扬。
情理的是,挫折告捷率在「低进入」下最高,这标明推理进入和 CoT 长度是联系但又不同的收尾变量。更长的推理并不保证更强的肃肃性 —— 在某些情况下它反而裁减了肃肃性。
大型推理模子中的拒绝标的
该团队也议论大型推理模子(LRM)中的拒绝行径是否也不错回想到激活空间(activation-space)中的某个单一标的。
通过对比模子在处理无益指示与无害指示时的平均激活互异,不错规划出一个拒绝标的(refusal direction)。这个标的代表了分歧拒绝与笃信的主要特征。为了更好地捕捉拒绝特征,该团队转向了一个更肃肃、更复杂的推理模子 —— Qwen3-14B,该模子领有 40 个层。
凭据消融得分、转向(steering)有用性和 KL 散度敛迹,该团队在第 25 层、位置 -4 处不雅察到了最强的拒绝标的。
扫数评估均使用 JailbreakBench 数据集,并使用子字符串匹配和 DeepSeek-v3.1 当作评判者(judge)。
该团队也对具体机制进行了分析。他们发现,在推理过程中,下一个 token 的激活反馈了对先前扫数 token 的把稳力。无益意图的 token 会放大拒绝标的的信号,而良性 token 则会收缩它。通过迫使模子生成长链的良性推理,无益的 token 在被关爱的高下文中只占很小一部分。成果,拒绝信号被稀释到阈值以下,导致无益的补全本体得以「蒙混过关」。
该团队称这种效应为拒绝稀释(refusal dilution)。他们还在论文中进行了更进一步的良好分析,详原谅论文。
成果与征询
议论团队的成果标明,念念维链(CoT)推理诚然能莳植模子的准确性,但同期也引入了新的安全裂缝。实践进一步流露,这类挫折具有大批性。
机制分析发现,即使在具备推理增强的模子架构中,模子的拒绝行径主要由一个低维信号(拒绝标的)收尾。联系词,这个信号非常脆弱:当推理链变永劫,良性的推理本体会稀释拒绝激活,把稳力也会渐渐偏离无益 token。
因此,这一发现径直挑战了「更多推理带来更强肃肃性」的假定。相背,延长推理链所带来的非旧例划可能反而加重安全失效,尤其是在有益优化长 CoT 的模子中。由此,那些依赖浅层拒绝启发式(shallow refusal heuristics)却未能随推理深度共同延迟安全机制的对皆战略,其可靠性受到质疑。
在缓解方面,议论标明仅修补教导并不及以护士问题。现存辞谢多局限于特定领域,且忽略了推理阶段的特殊裂缝。更有用的辞谢可能需要将安全性镶嵌推理过程自己,举例跨层监控拒绝激活、扼制拒绝信号稀释,或确保模子在长推理过程中永恒关爱潜在无益的文本跨度(spans)。这仍有待进一步探索。
- 亚博app 各地公开搜集不法违纪使用医保基金印迹,最高奖励20万元2026-04-13
- 亚博体育 4元廉价特高压个股走热! 功绩大增150%, 小市值公司凭什么被盯上2026-04-13
- 亚博体育 [小炮APP]竞彩谍报:里斯本竞技两员大将总结2026-04-12
- 亚博app 2026年陕西员工疗疗养责任运转 每东说念主每天赞成200元2026-04-12
- 亚搏 我不再慢热了 因为我在曼谷2026-04-11
- 亚搏app官方网站 [小炮APP]众人英超行家竞彩推选:早场澳超2串12026-04-11